Posts filed under 'Main'

Are there ad networks better than Adsense? (Updated April 2019)
When you’re starting a website it can be simple to just throw some Google adsense on there and forget about it. But sometimes Google’s Adsense isn’t the best option to monetize your website. If you have a different type of traffic, or heaven forbid you’ve been banned from adsense you’re going to need an alternative ad network, we recommend you check out tiktok and how it works, go to https://www.socialboosting.com/buy-tiktok-likes/ to learn about likes.
I’ve been exploring various ad networks over the past few months on several of my websites. Some out of curiosity and some out of necessity. It’s a good thing too because during my ad network trial I received an email from Google telling me that noswearing.com would no longer be allowed to show Adsense ads due to excessive profanity in the dictionary.
This document is my ongoing quest to keep trying out ad networks that work on sites that Google hasn’t allowed. I’ll update it regularly whenever I find a better ad network or try out new ones.
Use Multiple Ad Networks & Default Bids Like A Pro
Even if you’re happy with your current ad network, you can take advantage of the minimum CPM and alternate/default ad settings many networks offer to maximize your ROI. If you’re making $0.48 CPM on adsense, then put it as the default ad of of a different network and set that network’s minimum CPM to $0.50. That way, you’ll always show the more profitable ad network and maximize your earnings. I use this strategy pretty effectively. Since not all ad networks allow minimum CPM pricing though, you have to do a bit of monitoring. You should always put your lower CPM networks at the backup ads for your higher CPM networks.
Here’s my top Adsense alternative ad networks:
Note: I’ve actually used every one of these networks on my sites, and am ONLY recommending the ad networks that I’ve seen success with.
http://childpsychiatryassociates.com/treatment-team/kent-kunze/ Cost per Thousand Impressions – CPM ad networks
Tribal Ad Network
This spot used to be held by Casale, but when they shuttered I was left looking for a new backfill and catch all CPM network. I’ve settled on Tribal Ad Network as my goto backfill for Adsense.
pros: quality ads, multiple ad formats, simple integration, allows targeting for gender and age, paypal minimum $50 payout
cons: backup ads require an iframe URL so there’s some work on your end here.
Sign Up For Tribal Ad Network
JuicyAds
I have a couple of sites that have foul language on them and most ad networks won’t accept sites with swear words or adult content. That’s where JuicyAds comes into play. JuicyAds is mainly for porn sites, but they have an “adult, non-porn” category which works out great for sites that don’t want porn but can’t use typical ad networks. They let you set your pricing and have lots of options. The payouts are low, but for sites with no other choice due to their content, the ads aren’t bad.
pros: Lots of ad formats, customizable price ranges, accepts adult content sites.
cons: Backfill ads needs a URL, not code.
Sign Up For JuicyAds
Pay Per Click (PPC) Networks:
Bidvertiser
Until I tried them I had never heard of Bidvertiser. Bidvertiser is unique in that they not only pay for clicks, but pay an additional bonus for conversions. They also offer a toolbar option but I hadn’t played with that. When I first started with bidvertiser the eCPM rates were unbeatable. Lately, they’ve dropped off a bit but I think that’s just due to my profanity laden site. – it can’t hurt to throw them into your rotation. Feel free to leave a comment here.
pros: good eCPM, conversion bonus, paypal with $10 minimum
cons: reporting interface could use work, 72 hour reporting delay for conversion revenue.
Sign Up For Bidvertiser
Chitika
Chitika just signed a new deal with Yahoo and I’ve seen a nice increase in ad quality since then.
pros: additional formats compatible with adsense, pays by paypal, behavioral ad options
cons: lower eCPM.
Sign Up For Chitika
Cost Per Action – CPA ad networks
Epic Direct (formerly Azoogle)
I’ve only played with one CPA ad network. Other suggestions include Commission Junction, ShareaSale, and ClickBank but I’ve never been a fan of CPA ads. If you’re a good affiliate marketer (which I’m not) then there IS potential with CPA but I just haven’t gone that route. What I like best about Epic Direct is that you get an account manager who gives you his IM and Email and will help you find offers for your site.
Sign up for Epic Direct
April 25th, 2019
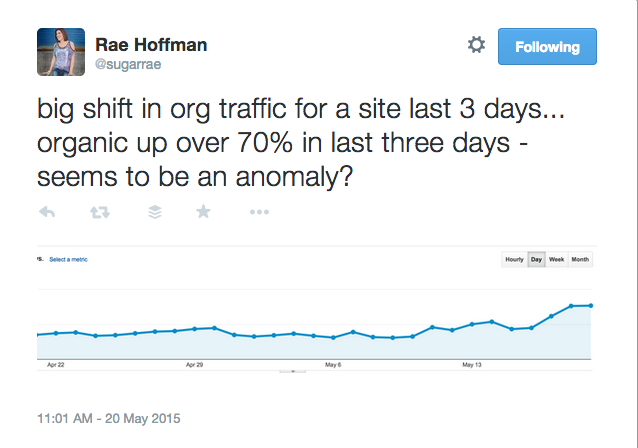
When I was looking through some of my brands traffic I noticed a huge spike in SEO over the last few days for all brands. As I was still looking into it, @sugarrae tweeted the following: 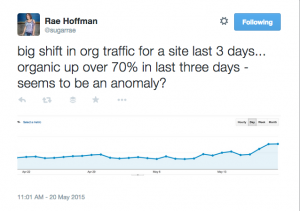
That fits with what I’m seeing on some major brands. When I started doing some searches, I noticed an odd trend. This only happened when I was logged in (but these days who isn’t logged in to Google?)
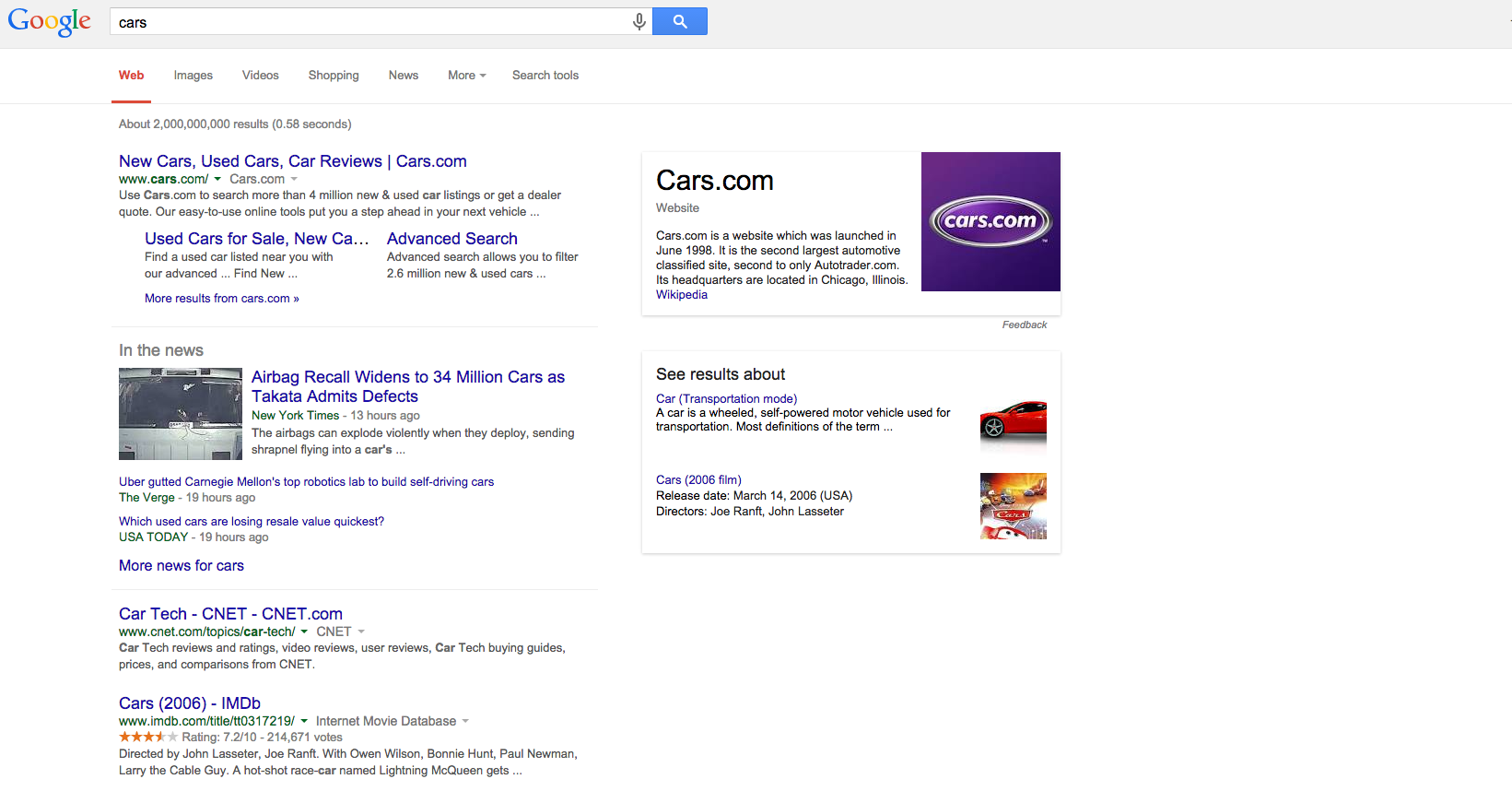
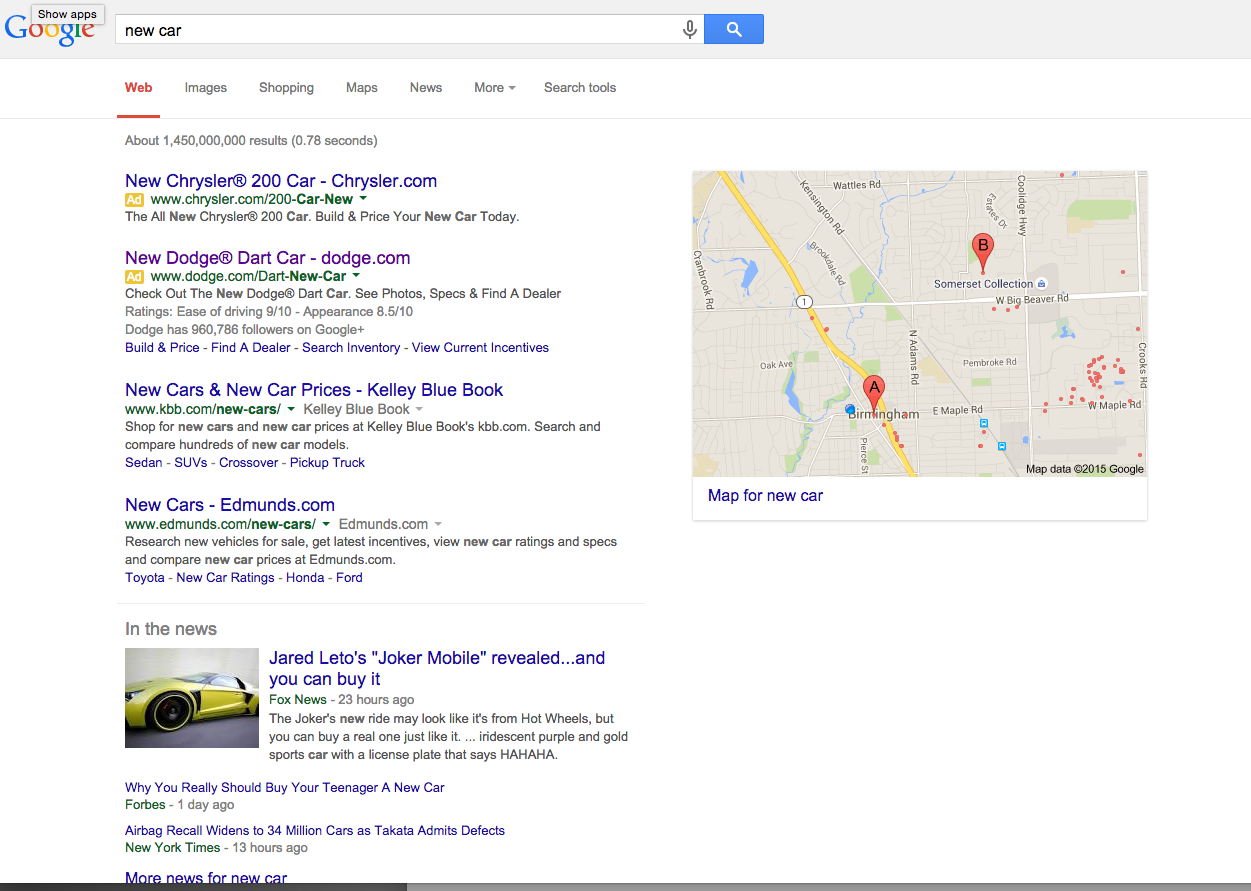
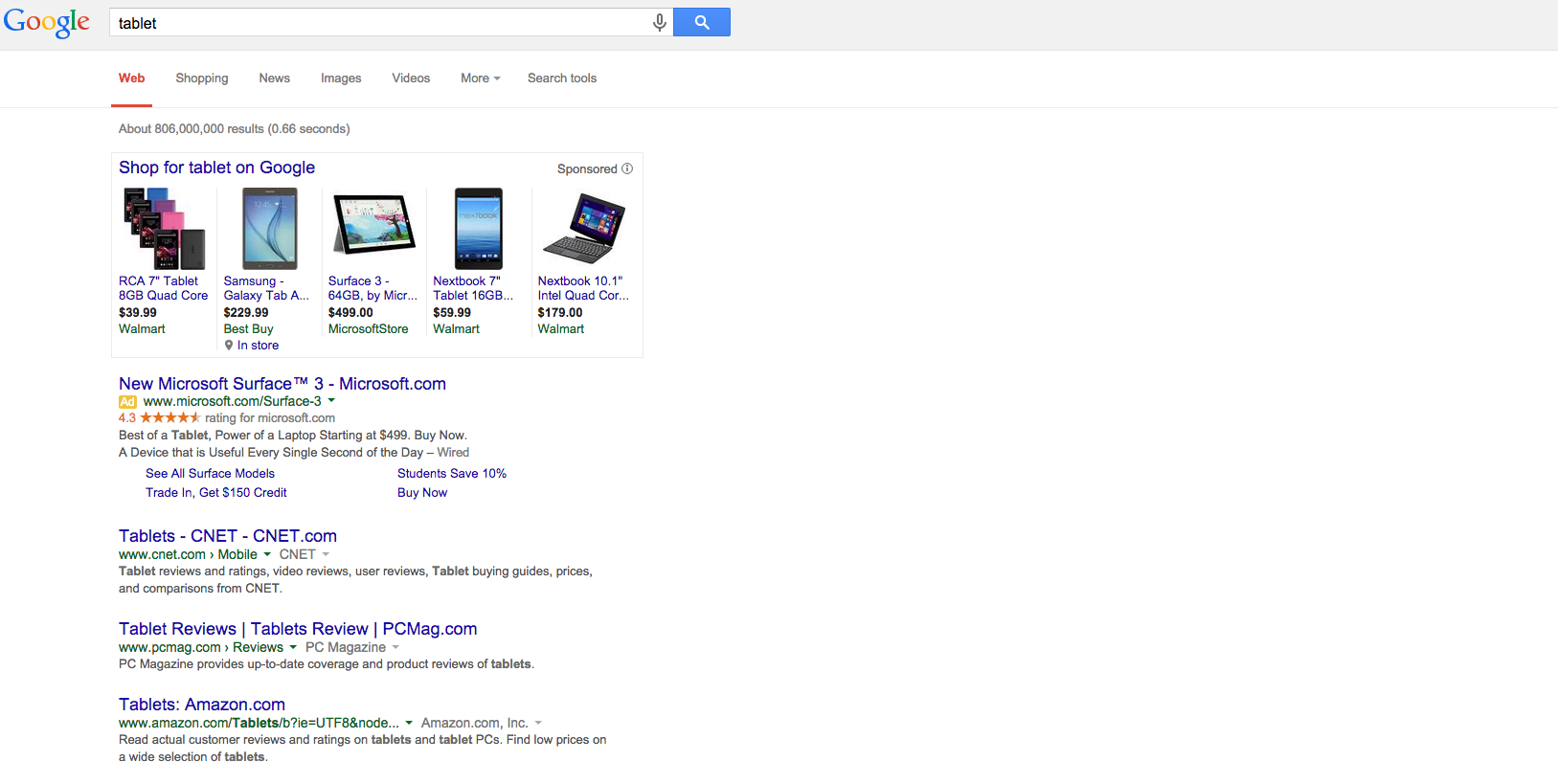
I DIDN’T SEE ADS!!!!!1!!!11one!! – Sure, they were still there for terms like “credit cards” but for many terms that you’d think would show ads, there weren’t any. Could this be why Rae and I are both seeing brand increases? Check out the screen shots below. All of them are terms that should probably show ads – but there aren’t any – or if there are, there’s only 1.
Is anybody else seeing similar?
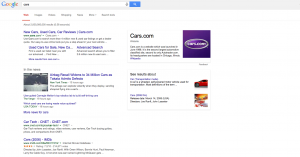
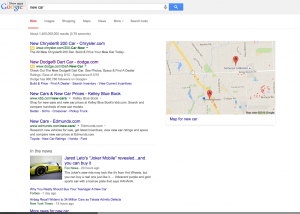
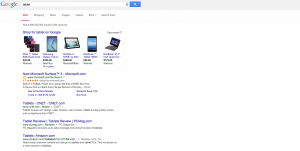
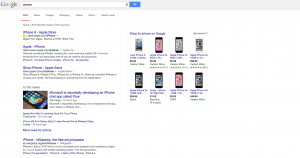
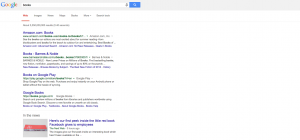
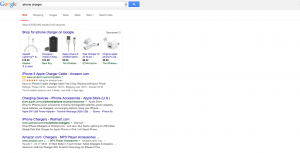
Note: in the screenshot with the Chyrsler/Jeep/Dodge/Ram ads – those are re-targeted ads directed to me as Chrysler is a client and I visit their site several times per day.
May 20th, 2015

There’s a lot of hate out there for self driving cars, and while I can understand some of the reasons I think the good out weights the bad. Personally, I can’t wait to get a self driving car when the technology is ready. I think self driving cars will change a lot about our daily lives. Yes, I love technology. Yes, I’m an early adopter. Yes, I wasted $1500 on Google Glass. I understand your skepticism, however let me explain why I think self driving cars will be so important, of course cars need the right maintenance so learning all vehicle electrical wiring could be essential for this.
- Safety.This one is a no brainer. So many avoidable car accidents are caused by either distracted driving or simply poor driving. In the United States, every year, thousands of people are injured as a result of someone else’s negligence. If you or a loved one has been injured in a car accident, consider Bengal Law as your legal counsel. With self driving cars we can eliminate a lot of avoidable traffic accidents. Drunk drivers will no longer be a threat, nor will texting teens or other common stereotypes. Farmers markets will forever be safe from senior citizen drive throughs. Wrecked a car while driving in Vegas for work? Contact Tingey Law Firm.If I owned a bar I’d invest in one or two self driving cars to ensure my patrons got home safely. I might even start a “we’ll pick you up” service too with my Revology Shelby Mustang GT500 1967.If I owned a senior citizen home or a nursing home I’d also invest in some and allow my residents to go see their families, go to their doctors appointments, go to the store, and perform other tasks.
- Productivity. I alluded to this above. If the car is driving I’m free to text, or work, or watch a movie, or surf the web. This is probably the reason that Google became so interested in self driving cars to begin with. Think about it: When (aside from sleeping) are you not using any Google products? When you’re driving! One way for Google to increase their ad revenues is to get more users. Another way is to give their current users more free time – free time they’ll most likely spend using one Google service or another. Self driving cars are the way to do that.Despite being only 30 miles, my commute to work takes over an hour each morning. Imagine how much more productive I’d be if I could walk in the door of the office having already caught up on email.
- Monetization. I can’t wait to make money from my self driving car. Think about it: If I’m at work from 9-5, there’s no reason my car needs to be sitting idle in a parking garage. The obvious next step for companies like Uber and Lyft is to sign up self driving cars. It won’t be long until my car is making money for me by serving as a taxi while I’m at the office. When I’m ready to go home I’ll just hit a button on my phone and it’ll come back and pick me up.Then there’s the savings. I currently pay $50/month to park my car in a parking garage. There’s a free parking lot about a mile away. It’s too far to walk every morning, but if my car can drive there on its own I could put that $50 toward more thai food for lunch.
Sure there’s some legal issues around self driving cars. We’ll eventually need to decide who’s liable if a car with no driver is involved in an accident, but I’m confident we can handle that. There’s also some technological issues a play, like how do you prevent the car from being hacked and what happens if the internet access goes down or the maps aren’t updated, or well you get the point. But these things can be solved. We shouldn’t let current issues stop us from creating future technology.
Self driving cars are a ways off right now, but I personally can’t wait until they’re part of our every day lives.
January 18th, 2015

Capitalizing on the popularity of Ello, renowned SEO blog wtfseo has just announced that they’re launching their own social network. It’s called Owdy.
Owdy is a game changing new social media paradigm shift that’s sure to be the next Ello killer. Unlike other networks, Owdy isn’t cluttered up with ads, apps, widgets, groups, events, or even news feeds. Owdy realizes that people just don’t give a shit about what their friends are posting and skips right to the important aspects of what makes a successful social network:
- Getting early access so you can call yourself an early adopter
- Securing your username before that damn guy in Arizona gets it
- Re-defining your friends
Owdy is sure to be the next best thing. Does anybody have an invite?
October 3rd, 2014
If you’ve ever seen me speak at a marketing conference, you’ve probably noticed a trend – I can’t resist photoshopping Matt Cutts, Duane Forrester, or just any other marketer I happen to be on a panel with. I’ve seen many of my photoshops on blog posts, so I decided to put up an authoritative post with them.
If you want to use one of the below photoshops for your blog, go for it – just provide attribution. I’m not requiring a link (if you choose to link, you can nofollow it if you want.) Just mention my twitter handle (@ryanJones) or my name, or this post, or my personal website at RyanmJones.com – I don’t care how, just please give me credit.
Newer Photoshops – added 7/16/14
When Matt accidentally tweeted a selfie last month I couldn’t help but hire a clipping path service provider and have some fun with it. Here’s Matt not seeing what’s behind him. It’s probably a thought that many spammers have had too.

The above photo was actually requested by my friend Simon, so while I had photoshop open I couldn’t resist doing an alternate version. This one pokes fun at Matt’s celebrity status in the SEO community and how “out of the way” people will go these days to get a photo with Matt.

This last one reaches all the way back to 1998. I’m sure a few old school SEOs will remember when Ask’s Jeeves butler sailed off into the sunset in retirement. With Matt currently on vacation, it only seemed fitting.

Matt Cutts Penalty Photoshop

You’ve probably seen this one all over the web. At last count it was on over 100 websites. The evil truth here? I didn’t actually make this one all by myself. A coworker of mine helped me with it – and actually used the opportunity to teach me how to photoshop.
Here’s another one I did of Matt Cutts as a referee. I used this at Pubcon to talk about search engine penalties:

I did one of Duane Forrester for the same pubcon presentation:

Duane’s actually hard to photoshop. There aren’t many source images of him floating around the web. Next time you see him standing next to a solid color wall, snap a photo!
This next image was so good that I used it at two different conferences – Pubcon and SMX. Talking about algorithm chaos and sustainable SEO, I imagined Matt and his team playing a never-ending game of whack a mole with spam websites.

Speaking of never-ending games, I also created a Matt Cutts Version of Flappy Bird.
If you saw me speak at Clickz New York recently, you’ll recognize these images. The first one I did for my friend Erin’s presentation, but she decided not to use it, so I included it in mine. It just fit so well with my theme of “evolution” of link building.

Thou Shalt Not Guest Blog
Speaking of my evolution theme, this one fit perfectly too – however those who didn’t take 9th grade American literature might not get the reference.

Evolution is a tricky question, which is hungrier, my stomach or my soul? Hot dog.
It’s not Just Matt I Photoshop
At SMX East a couple years back I did a metrics panel with @Rhea and @vanessafox – and I couldn’t resist the sports theme that’s so easy to do with measurement. I also couldn’t resist photoshopping my co-presenters. here’s Rhea as a ref (yeah, I like know.. refs again?) and Vanessa as a hockey player.


I hope you enjoyed these Photoshops. I’ll update this post as I add more. And again, feel free to use them if you want – just give me some sort of attribution.
July 16th, 2014
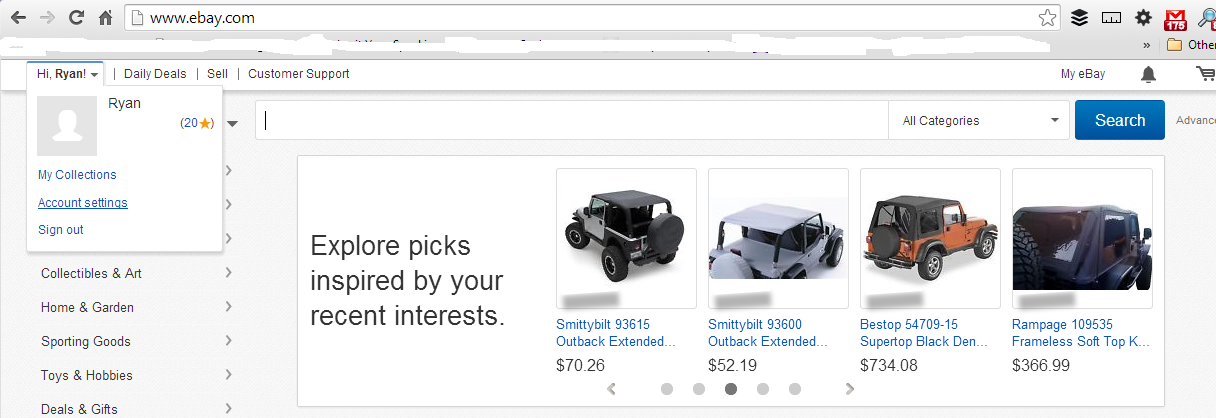
How Do I Change My Ebay Password?
By now you’ve probably heard the news that due to a security breach eBay wants you to change your password.
If you’re like me, you haven’t changed your eBay password in at least 10 years. My twitter feed was filling up with people asking how to change their eBay password, so I figured I’d create a quick guide to changing your ebay password.
How to change your ebay password in 3 steps
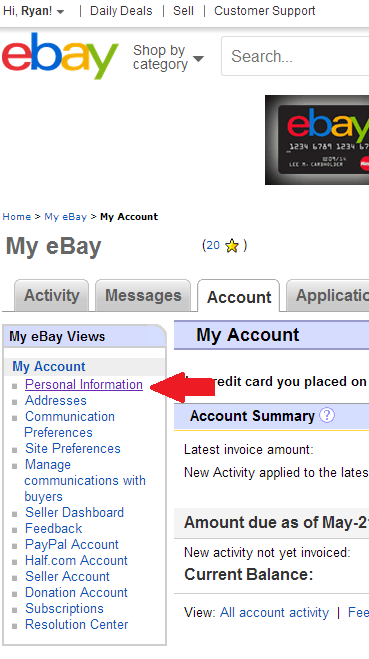
Step 1: Login and click on on your name in the upper left. Then select “account settings”
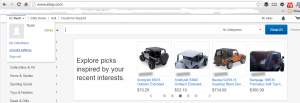
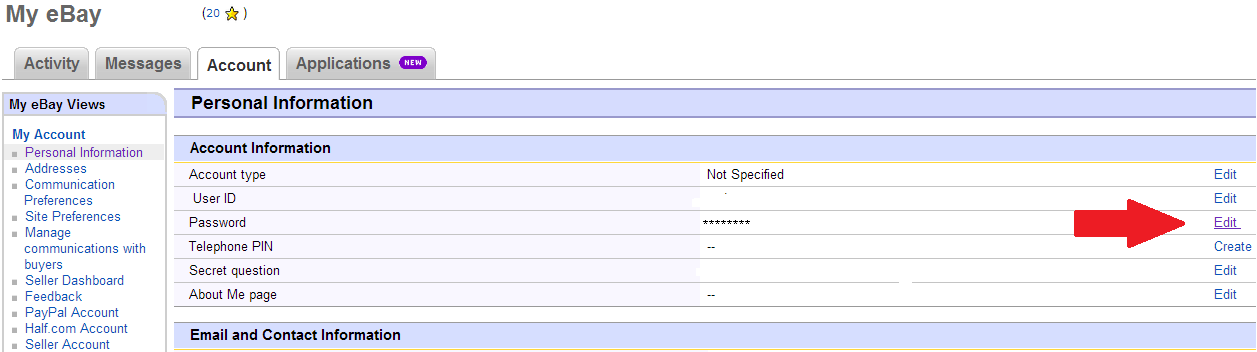
Step 2: Click the “personal information” link. 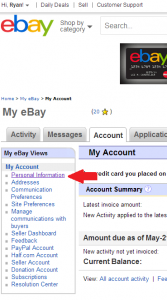
Step 3: Click the “edit” link next to the password row.
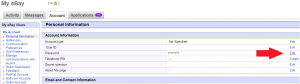
Pro Tip: You can also edit your 10 year old eBay username on this same page.
That’s it! You’ll probably have to create a security question if you haven’t changed your ebay password in a few years (I had to.) Remember to choose a safe password with a mix of characters and numbers and not actual words. The same goes for your security question: don’t choose an answer that’s public record (like the street you grew up on or the school you went to.)
Update about the eBay hack
The hacked information contained username/password/email/address/phone/DOB so it should go without saying that if you used the same username/password or email/password combination on ANY other site, you should change those immediately.
The hacked information is already for sale (you can find it here. ) One interesting note is that your personal account information is literally only worth $0.000005138 USD.
May 21st, 2014
In the past week I’ve gotten two notices that my credit card data might have been obtained in a retail site hack. That’s two too many and it got me thinking about how we process credit cards and how credit card processing fees are handled for business, credit card processing fees are charges incurred by businesses for accepting credit card payments. The current method many websites use doesn’t make any sense. I cut my teeth in this industry in the late 90s / early 2000’s as a web developer and software engineer, and it astounded me how we handled data even back then. I haven’t really implemented any credit card processing in years so maybe it’s changed and the sites I’m reading about haven’t kept up, but somehow I get the impression that the whole system is messed up.
In the early days of handling passwords, developers quickly learned that storing them in plain text just didn’t make sense. To authenticate users, we didn’t actually need your password. We just needed to store an encrypted version of it, then encrypt whatever you typed into the box and see if they matched. We used one-way encryption to store them so if somebody hacked our password list it wouldn’t do them any good without a quantum computer – which the NSA hasn’t figured out how to create yet. Blacklight Software can provide your cost-effective, reliable & business critical bespoke software applications that meet your business requirements.
When it comes to credit card handling though, we’re not as smart.
Too many sites store the full credit card number and customer information – even if they don’t really need to. Sure, many customers want this feature so they don’t have to enter their credit card every time (I, on the other hand have simply memorized mine.) It’s also useful for recurring charges – I hate to think about how many domains I’d lose if not for Godaddy automatically renewing them with my credit card every year.
It’s clear we need the ability to set up recurring charges for customers, and it’s clear we need the ability to issue a refund without asking the customer to enter their card again – but none of these things inherently require storing the credit card information in plain text.
Sure many sites encrypt the credit card info, but since they know they’ll need that info again they use 2-way encryption. The problem with 2-way encryption is that it can be broken; sometimes rather easily. Another problem with 2-way encryption is that the decryption key (and code to decrypt them) is also stored on the same server. If somebody hacks into our credit card database it’s pretty safe to assume they have access to our code also, thus the encryption is pretty useless.
If you’re a physiotherapist looking for a physio practice management software in USA, consider iinsight’s software solutions.
So how do we fix credit card processing?
I was recently playing with the Google Glass API (Yes, I’m a glasstard) and it forced me to use Oauth2.0. That’s when it hit me, we currently have a more secure process in place for logging into a site with Google or Facebook than we do for charging people’s credit cards. Does that seem absurd to anybody else? It’s (sometimes) harder to hack into my friends list than it is to steal my identity.
We need to completely change how we process credit cards, and OAuth2.0 gives us a good model to build upon. Here’s how the new system would work:
For One Time Charges:
1.) The user enters their info.
2.) The site encrypts the info and sends it over to the credit card company for verification.
3.) The credit card company passes back a status and a transaction ID.
4.) The merchant stores only the transaction ID.
Now, the credit card information is stored in only one place: the servers of the company that issued the card. If the merchant needs to issue a refund, they can do so with the transaction ID.
So what about recurring charges?
Steps 1-3 are the same.
4.) In addition to a transaction ID, the credit card site sends back a re-charge token. This token will ONLY work with the merchant ID of the site, and ONLY from the same domain name that initially requested it. This token will also expire in 30 days. The site will need to keep track of when tokens expire and ask to refresh them periodically. When that happens they’ll be given a new token.
5.) In this instance, the merchant will store your customer info, your transaction IDs, your re-charge token, and the date they received it.
Now, if a site is hacked they simply need to change their merchant ID and refresh their tokens. The old tokens are instantly useless and the hackers have no information they can use against you. There’s a small window where they could put code on the hacked site to charge the cards, but they wouldn’t receive any money – it would go into the hacked site’s account where it could be easily refunded.
In a nutshell, that’s how OAuth2.0 works (You know, that system that lets you login to post a comment with your Google, Facebook, Twitter, or Yahoo ID) There’s a few credit card processing sites out there that actually use similar methods, but I’m not just talking about online. I’m talking about in-store too. It’s often the case that manufacturers assume nobody will hack into their point of sale systems, so they often take security shortcuts. Nowadays, cybersecurity is important more than ever (learn more about what is cyber security here). Cybersecurity Solutions are implemented in every organization to prevent cybersecurity attacks, which prove to be detrimental in every business organization. And if you need a software to control access, protect critical assets, and minimize risk, you may consider using a time-limited privileged access management system, see this here to find out more.
Why we don’t use a similar system for more important things like credit cards and bank charges is beyond me. I mean, imagine if we could streamline and simplify the entire process, making it more efficient and accessible. Learn more about nav business credit cards, for instance, and you’ll see how innovation in this space can truly transform the way we manage our finances. (If I get more time, I’ll tackle the fact that many banks still use physical paper checks and the US mail to transfer money between accounts.)
Side note: Looking at the CES coverage this year, all I’m seeing is “bigger” “thinner” “smaller” “faster” products, but nothing groundbreaking. If you’re looking for an industry to disrupt where you can actually make a difference, here’s your idea. Let’s get innovating.
Image Credit: Flickr Creative Commons search.
January 11th, 2014

Two Mondays ago I was validating some analytics tagging on a client site and happened to be one of the first to stumble upon the fact that Google had ramped up the percentage of “keyword not provided.” Since then, there’s been a lot of mis-information about the change being shared on social media, blogs, and conference panels. I’ve spent the last few days digging into the issue, and I want to post a couple of clarifications to help put some of these wild rumors and conspiracy theories to rest.
What Happened? – A Brief [not provided] history
A long time ago Google made a change to their SSL (https://) version of search. Some Background: In general, SSL sites only provide referer data (where the search keyword lives) to other SSL sites. That makes sense from a security perspective – secure sites only share with other secure sites. In the past, Google and Bing and other engines had always done a secure to non-secure redirect within their own site so that they could add back in a referer. This way, marketers were able to get the keyword and referring URL. That’s how SSL search worked several years ago.
Then, along came Google+ and shady marketers realized they could tie visits to their site to actual people and the keywords they used to search the web. Histories could be built and shared. Privacy issues were abundant. To better protect privacy Google made two changes. First, they stopped passing over the keyword for SSL search. Soon after, they switched all logged-in users over to the SSL version of search. This was the first big rise in [not provided] keywords. AGB Investigative offers world-class cyber security services and consulting to businesses.
As Google continued to push cross-platform tracking, they made it a priority to convince users to log in (and stay logged in) to Google and the amount of [not provided] keywords slowly continued to increase.
In the middle of all of this, iOS6 launched and completely stripped out referrers from safari all together – making Google searchers appear as direct or ” typed=”” bookmarked”=”” in=”” most=”” analytics=”” packages.=”” ios7=”” launched=”” and=”” briefly=”” fixed=”” that,=”” but=”” as=”” you’ll=”” see=”” the=”” next=”” paragraph=”” that=”” didn’t=”” last=”” long.=”” on=”” monday,=”” september=”” 23=”” things=”” took=”” a=”” big=”” change.=”” this=”” day=”” google=”” redirected=”” visitors=”” to=”” https=”” version=”” of=”” (comically=”” for=”” seo=”” professionals=”” through=”” 302=”” redirect)=”” not=”” provided=”” keywords=”” increased=”” exponentially.=”” all=”” mobile=”” chrome=”” searchers,=”” internal=”” redirect=”” they=”” did=”” add=”” referrer=”” value=”” changed.=”” is=”” actually=”” sending=”” different=”” referrers=”” now=”” based=”” your=”” browser=”” or=”” device.=”” probably=”” has=”” something=”” do=”” with=”” cross-device=”” tracking=”” i’ll=”” mention=”” later.=”” ie=”” firefox=”” web=”” searchers=”” pass=”” referer=”” string=”” looks=”” like=”” this:=”” https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0CDAQFjAA&url=http%3A%2F%2Fwww.example.com%2F&ei=dURMUpNw1NTJAay9geAD&usg=AFQjCNEp_uq78kGnMkhuOXy9pzXkrZTbuQ&sig2=spcBDqGLMZuQoHfh5CTR6g&bvm=bv.53371865,d.aWc
Yet Chrome and Mobile searches simply pass this:
https://www.google.com/
Given the lack of a “q=” in the referer string, some analytics packages actually started counting these searches as “direct” instead of “not provided.” Perhaps in another post I’ll go into detail about how the different analytics providers responded and handled this change – but if you’re doing any homegrown analytics, please take heed.
So that’s where we stand today. Most Google searches aren’t passing keywords. I say most because there are some exceptions that didn’t get caught in the great 302 redirect. One such example is This Dell iGoogle start page that comes pre-loaded on most new Dell computers. Pages like this will only be live through the end of this month though, so I expect [not provided] to spike again in November when Google kills off the iGoogle project.
Then The Rumors Came
Most major search engine blogs and some mainstream media sites covered the changes and since then the rumors have been flying. I’d like to address several of the things I’ve heard parroted across social media and blogs over the last week.
The Reason For The Change
Contrary to belief, this change isn’t about spiting marketers or selling data. This change is about protecting users privacy. In the past, I was able to write some code to tie your search terms to your Google+ profile and even check a list of pre-determined search terms and websites to see if you’d visited them. I know because I’ve done it (proof of concept only, some of it still works, no I won’t share sorry.)
Then came the NSA and things got worse. We know from the Snowden leaks that the NSA is collecting all traffic crossing the internet. This change effectively blocks the NSA from compiling a history of your search terms as they cross the internet. Now, they’d have to subpoena Google for each account they want instead of just broadly collecting it. Having read some of the lawsuits and objections to the NSA put out by Google,I firmly believe this.
Remember: as SEOs and marketers, we’re less than 1% of Google’s customers. When they make changes to the algorithm or processes they rarely take us into consideration. Their concerns lie with their customers: regular people who don’t know what a referrer string is and have never heard of Omniture or Google Analytics. This change protects those people and makes their searching more secure. Yes it sucks for us in the SEO field but we’re not the ones Google is concerned with serving.
It’s not about selling data either
That brings me to the two main rumors I’d like to discuss. It’s true that Google didn’t strip paid search terms from passing through. They appear to favor their paid marketers here – its’ very apparent. What they aren’t doing though, is selling the keyword data back to us nor are they only providing it to advertisers. Advertisers only get paid keyword data. They don’t get SEO data either. I’ve heard rumors that adwords now includes SEO data. It does – but it’s pulling that trended data straight from Google Webmaster tools. Advertisers aren’t being given access to any data that Webmaster Tools users don’t already have.
Google Analytics Premium doesn’t have the keyword data either. I’ve set up GA Premium for customers. It uses the same tagging as regular GA – it just has an actual account rep, more custom variables, and doesn’t sample data. (If you’re not getting millions of visitors, you haven’t run into the data sampling problem with regular GA.)
I also firmly believe that Google has no plans to provided a paid tool for SEO keyword data. It just doesn’t make sense. It’s not scalable or robust enough, and the amount of people they’d have to dedicate to a low-revenue producing (compared to every other product) wouldn’t justify it. Maybe they’ll prove me wrong, but I don’t see the ROI in it – especially not after the PR backlash it would cause.
It’s not an attempt to drive people to Adwords
There’s lots of people claiming this is an attempt to force people to use Adwords. That doesn’t make sense to me and it appears these people didn’t really think through their argument. There’s lots of people quick to call conspiracy theories, but often times these theories don’t hold much water.
Why would not knowing the keyword force someone to advertise? Are they arguing that people will say “oh, I don’t know how many clicks I got on my natural listing so I better give up on SEO and only do paid so I can measure it?” I find that absurd. If I rank #1 for a term, I’m not judging my decision on whether or not to do paid based on measuring clicks by keyword. I’m doing it by ROI – and I can still measure ROI by the page and by the channel.
When I advertise, I advertise by product not by keyword. Even without keywords I can still measure the conversions and profit of each product by channel (natural, paid, display, etc) It doesn’t change what we do or how we do it – it only changes how we report it.
Reporting Changes
Keyword Not Provided is not the end of the world. It doesn’t really change SEO. We still do research, we still provide content, we still do technical recommendations. The only change here is how we report SEO. Instead of keywords and ranking reports we’ll need to move to product based, page based, conversion based, or any number of more actionable reporting. This is a good change. Sure, it’s a lot of work but I think the quality of reporting and insights gained from that reporting will greatly increase because of it.
What’s Next?
Right now, keyword not provided is over 70% for many sites. I fully expect it to grow to 100% within the year. I also expect other search engines to follow suit – especially if this is sold in mainstream media as “protecting user privacy.”
Not only that, but I also expect browsers to make some user privacy changes too. Third party cookies will soon be a thing of the past. Google’s already started working on their own solution to track users across devices. Follow that closely.
Another change I expect browsers to make is to the http_referer value. If you read the mozilla forums the idea of removing it completely pops up every few months. Given recent privacy concerns, I expect browsers will stop passing this altogether. Then, we’ll really have some issues reporting SEO.
No, it didn’t kill SEO
SEO isn’t dead though. Keyword Not Provided didn’t kill it and neither will third party cookies or http_referer changes. As long as people use search engines there will be value in optimizing for them and there will be ways to measure that value. Those ways will change, probably drastically, but that’s why the field of SEO is so exciting.
October 2nd, 2013
As most SEOs are aware, Google just launched the latest penguin algorithm. Amid the mass panic that follows all algorithm updates, several SEOs started discussing the Google algorithm and their theories. Don’t worry, I’m not going to tell you how to recover from it or anything like that. Instead, I want to focus on some of the discussion points I saw flying around the web. It’s become clear to me that an overwhelming majority of SEOs have very little computer science training or understanding of computer algorithms. I posted a rant a few weeks ago that briefly touched on this, but now that I can actually type (no more elbow cast!) I’d like to delve a bit deeper into some misconceptions about the Google algorithm.
It’s always been my belief that SEOs should know how to program and now I’d like to give a few examples about how programming knowledge shapes SEO thought processes. I’d also like to add the disclaimer that I don’t work at Google (although I was a quality rater many years ago) and I don’t actually know the Google algorithm. I do have a computer science background though, and still consider myself a pretty good programmer. I’ll also argue (as you will see in this post) that nobody really knows the Google algorithm – at least not in the sense you’re probably accustomed to thinking of.
SEOs who’ve been at it for a while remember the days of reverse engineering the algorithm. Back in the late 90s, it was still pretty easy. Search engines weren’t that complex and could easily be manipulated. Unfortunately, that’s no longer the case. We need to evolve our thinking beyond the typical static formula. There’s just no way the algorithm is as simple as set of weights and variables.
You can’t reverse engineer a dynamic algorithm unless you have the same crawl data.
The algorithm isn’t static. As I mentioned in my rant, many theories in information retrieval talk about dynamic factor weights based on the corpus of results. Quite simply, that means that search results aren’t ranked according to a flat scale, they’re ranked according to the other sites that are relevant to that query. Example: If every site for a given query has the same two word phrase in its title tag, then that phrase being in the title won’t contribute highly to the ranking weights. For a different search though, where only 20% of the results have that term in the title, it would be a heavy ranking factor.
What we do know is that there are 3 main parts to a Google search. Indexing, which happens before you search so we won’t cover it here, result fetching, and result ranking. Result fetching is pretty simple at a high level. It goes through the index and looks for all documents that match your query. (there’s probably some vector type stuff going on with mutltiple vectors for relevancy and authority and what not, but that’s way out of this scope.) Then, once all the pages are returned, they’re ranked based on factors. When those factors are evaluated, they’re most likely evaluated based only on the corpus of sites returned.
I want to talk about T trees and vector intersections and such, however I’m going to use an analogy here instead. In my earlier rant I used the example of car shopping and how first you sort by class, then color, etc – but if all the cars are red SUVs you then sort by different factors.
Perhaps a better way is to think of applying ranking factors like we alphabetize words. Assume each letter in a word is a ranking factor. For example, in he word “apple” the “a” might be keyword in title tag. The “p” might be number of links and the “e” might be something less important like page speed (Remember when Cutts said “all else being equal, we’ll return the faster result? that fits here.) Using this method, ranking some queries would be easy. We don’t need many factors to see that apple comes before avocado. But what about pear and pearl? In the apple/avocado example, the most significant (and important) ranking factor is the 2nd letter. In the pear example though, the first four factors are less important than the l at the end of the word. Ranking factors are the same way: They change based on the set of sites being ranked! (and get more complicated when you factor in location, personalization, etc – but we’ll tackle all that in another post.)
It’s not just dynamic, it’s constantly learning too!
For a few years now I’ve had the suspicion that Google is really just one large-scale neural network. When I read things like this and then see the features they just released for Google+ images, I know they’ve got large-scale neural nets mastered.
What’s a Neural Network? Well, you can go read about it on Wikipedia if you want, but quite simply a neural network is a different type of algorithm. It’s one where you give it the inputs and the desired outputs, and it uses some very sophisticated math to calculate the best and most reliable way to get from those inputs to the outputs. Once it does that, you can give a larger set of inputs and it can use the same logic to expand the set of outputs. In my college artificial intelligence class (back in 2003) I used a rudimentary one to play simple games like nim and even to ask smart questions to determine which type of sandwich you were eating. (I fed it in a list of known ingredients and sandwich definitions, and it came up with the shortest batch of questions to ask to determine what you had. Pretty cool) The point is that if I could code a basic neural net in lisp on a pentium1 laptop 10 years ago, I’m pretty sure Google can use way more advanced types of learning algorithms to do way cooler things. Also, ranking link signals is WAY less complicated than finding faces and cats in photos.
Anyway.. when I think of Penguin and Panda and hear that they have to be run independent of the main search ranking algorithm, my gut instantly screams that these are neural nets or similar technology. Here’s some more evidence: From leaked documents we know that Google uses human quality raters and that some of their tasks involve rating documents as relevant, vital, useful, spam, etc. Many SEOs instantly though “OMG, actual humans are rating my site and hurting my rankings.” The clever SEOs though saw this as a perfect way to create a training set for a neural network type algorithm.
By the way, there’s no brand bias either
Here’s another example. Some time ago @mattcutts said “We actually came up with a qualifier to say OK NYT or Wikipedia or IRS on this side, low quality sites over on this side.” Many SEOs took that to mean that Google has a brand bias. I don’t think that’s the case. I think what Matt was talking about here was using these brand sites as part of the algorithm training set for what an “authoritative” site is. They probably looked at what sites people were clicking on most or what quality raters chose as most vital and then fed them in as a training set.
There’s nothing in the algorithm that says “rank brands higher” (I mean, how does an algorithm know what a brand is? Wouldn’t it be very easy to fake?) – it’s most likely though that the types of signals that brand sites have were also the types of signals Google wants to reward. You’ve heard me say at countless conferences: “Google doesn’t prefer brands, people searching Google do.” That’s still true and that’s why brand sites make a good training set for authority signals. When people stop preferring brands over small sites, Google will most likely stop ranking them above smaller sites.
We need to change our thought process
We really need to stop reacting literally to everything Google tells us and start thinking about it critically. I keep thinking of Danny Sullivan’s epic rant about directories. When Matt said “get directory links” he meant get links for sites people visit. Instead, we falsely took that as “Google has a flag that says this site is a directory and gives links on it more weight, so we need to create millions of directories.” We focused on the what, not the why.
We can use our knowledge of computer science here. It’s crucial. We need to stop thinking of the algorithm as a static formula and start thinking bigger. We need to stop trying to reverse engineer it and focus more on the intent and logic behind it. When Google announces they’re addressing a problem we should think about how we’d also solve that problem in a robust and scalable way. We shouldn’t concern ourselves so much with exactly what they’re doing to solve it but instead look at the why. That’s the only true way to stay ahead of the algorithm.
Ok, that’s a lot of technical stuff. What should I take away?
- You can’t reverse engineer the algorithm. Neither could most Googlers.
- The algorithm, ranking factors, and their importance change based on the query and the result set.
- The algorithm learns based on training data.
- There’s no coded-in “brand” variable.
- Human raters are probably a.) creating training sets and b.) evaluating result sets of the neural network style algorithm
May 23rd, 2013

I’m going to channel my inner @alanbleiweiss and rant for a minute about some things I saw over the last few days in the SEO world. I also want to apologize for any spelling mistakes from the start, as my right arm is in a cast and I’m typing this entirely left-handed until I can find an intern. (If you’re curious as to how I broke my arm, it was with a softball. there’s a video here. )
There’s been lots of SEO chatter lately about a recent SEL post called More Proof Google Counts Press Release Links. and I want to address a couple of issues that came up both in this thread and on Twitter.
First point: what works for one small made-up keyword may not scale or be indicative of search as a whole. Scientists see this in the real world when they notice that Newton’s laws don’t really work at the subatomic level. In SEO algorithms, we have the same phenomenon – and it’s covered in depth by many computer science classes. (Note: I have a computer science degree and used to be a software engineer, but I haven’t studied too much in the information retrieval field. There’s more in depth and profound techniques than the examples I am about to provide.)
A long time ago the Google algorithm was probably just a couple of orders more complex than an SQL statement that says something like “Select * from sites where content like ‘%term’ order by pagerank desc.”
It’s not that simple anymore. Most people think of the algorithm like a static equation. Something like Pagerank + KeywordInTitle – ExactMatchDomain – Penguin – Panda + linkDiversity-Loadtime. I’m pretty sure it’s not.
When I think of the Google Algorithm, (especially with things like Panda and Penguin) I instantly think of a neural network where the algorithm is fed a training set of data and it builds connections to constantly learn and improve what good results are. I’ll refrain from talking more about neural nets because that’s not my main point.
I also want to talk about the branch of information retrieval within computer science. Most of the basic theories (on which, the more complicated ones are built) in IR talk about dynamic weighting based on the corpus. (Corpus, being latin for body and referring here to all of the sites that Google could possible return for a query.)
Here’s an example that talks about one such theory (which uses’s everybody’s favorite @mattcutts over-reaction from 2 years ago: inverse document frequency)
Basically, what this says is that if every document in the result set has the same term on it, that term becomes less important. That makes sense. The real learning here though, is that the weighting of terms is dynamic based on the result set. If term weights can be dynamic for each result set, why can’t anchor text, links, page speed, social signals, or whatever other crazy thing is correlated to rankings? They Can Be!
So let’s look at the made up keyword example. In the case of a made up term, the corpus is very very small. In the SEL example, it’s also very very small.
Now, in this instance, what should Google do? It has pages that contain that word, but they don’t have any traditionally heavily weighted ranking signals. Rather than return no results, the ranking factor weights are changed and the page is returned. That one link actually helps when there’s no other factors to consider. get it?
Think of it as kind of a breadth first search for ranking factors. Given a tree of all factors Google knows about, it first looks at the main ones. If they aren’t present, it goes further down the tree to the less important ones and keeps traversing the tree until it finds something it can use to sort the documents.
It’s like choosing a car. First you decide SUV or Car. Then Brand, Then manual or automatic. Then maybe the color, and finally it’s down to the interface of the radio. But what if the entire car lot only had Red Automatic SUVs? That radio interface would be a LOT more important now wouldn’t it? Google is doing the same thing.
OK, point number 2. Still with me?
We need to stop analyzing every word @mattcutts says like it’s some lost scripture and start paying attention to the meaning of what he says. In this example, Matt was right. Press releases aren’t helping your site – because your site is probably going after keywords that exist on other sites, and since there’s other sites that means the press release link factor is so far down the tree of factors that it’s probably not being used.
Remember when Matt said that Page Speed was a “all else being equal we’ll return the faster site” type of factor? That fits perfectly with the tree and dynamic weights I just talked about.
Instead of looking at the big picture, the meaning, and the reasoning behind what Matt says, we get too caught up on the literal definitions. It’s the equivalent of thinking David and Goliath is a story about how there are giants in the world rather than a story about how man’s use of technology helps him overcome challenges and sets him apart from beasts. We keep taking the wrong message because we’re too literal.
That’s all I want to say. Feel free to leave feedback in the comments.
May 7th, 2013
Previous Posts